Different Types of Load Balancing Algorithm Techniques
- November 20, 2017
- 0
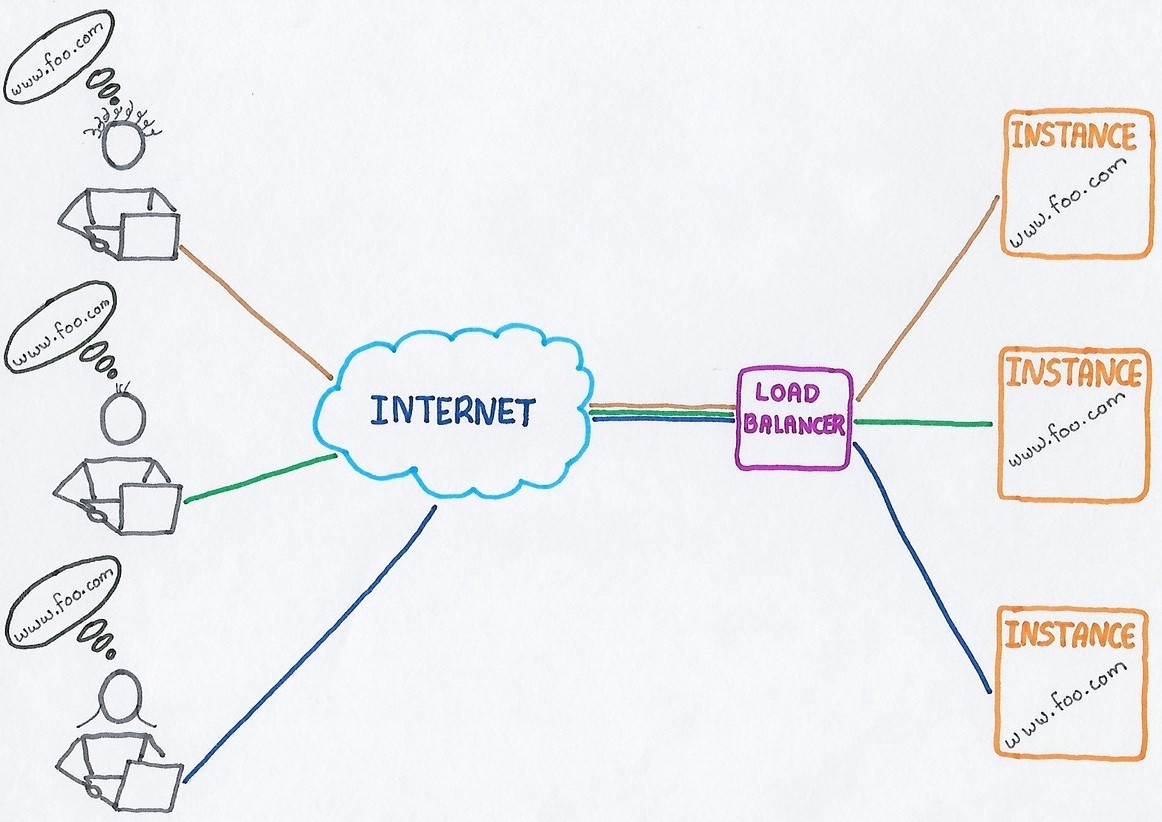
Load balancing can be explained as the intelligent distribution of data (workloads) among multiple computing services (server pool) in order to provide reliability, redundancy, and for improving the performance.
A load balancer serves as the “traffic manager” of your servers, routing client requests equally across all available servers ensuring no server is overloaded, which might degrade the performance. It also ensures no server is idle and provides a flexibility of addition or subtraction of servers as per demand.
Load balancing algorithm techniques
The load balancing algorithm used determines the selection of backend servers to forward the traffic. This is based on:
i) Server health
ii) Predefined conditions
Different types of load balancing algorithms are meant for different benefits and the choice depends on your needs. To implement load balancing, a load balancer coupled with at least one more additional server is required. Depending on the distribution of the load, whether it is on the network or application layer, algorithms widely vary. Some of the efficient, frequently used network layer load balancing algorithms include:
1. Round Robin Algorithm
This involves a cyclical sequential distribution of request to servers and is ideal for a throng comprising of identical servers.
The two types in Round robin are:
i) Weighted round robin: It can be used effectively for a cluster of unidentical servers as each server is assigned a weight based on its structure and efficiency. It also follows a cyclical procedure but the server preference happens according to the preassigned efficiency. Thus, efficient servers are loaded more. Besides the server capacity, it is preferred if one server should get a substantially lower number of connections than an equally capable server, since the first server runs critical applications and it should not be easily overloaded.
ii) Dynamic round robin: It forwards the requests to the associated server based on a real-time calculation of server weights.
2. Least connections
Here, the relative computing capacity of each server is monitored and the server with least active transactions is selected to distribute the load.
3. Weighted least connections
The load distribution is based on both the number of active connections to each server and the relative server capacity.
 4. Source IP hash
4. Source IP hash
The selection of back-end server is based on a hash of the source IP of the request, like the IP address of the visitor. The distribution is altered if a web node fails and becomes out of service. As long as all servers are running, a particular user is consistently connected to the same server.
5. URL hash
Hashing is performed on the request URL. This avoids duplication cache, by storing the same object in several caches, thus the effective capacity of the backend caches is increased.
6. The least response time
The backend server is selected in preference with the least response time, ensuring the end client receives an immediate response.
7. The least bandwidth and the least packets method
The back end server is decided by the load balancer depending on the bandwidth consumption for the last fourteen seconds. The associated server which consumes the least bandwidth is selected. Similarly, at least packets method, the server transmitting the least packets receive new requests from the load balancer.
8. The custom load method
The servers are chosen depending on their load, which is calculated based on the CPU usage, memory and response time. The server load is evaluated by load monitor. Resource utilization can be established efficiently by this method.
Even these algorithms are sufficient in predictable traffic scenarios, they are not that effective in dealing with uneven or unexpected server loads.
Application layer algorithms
Here the requests are dispersed according to the content of the request to be processed, including the session cookies along with the HTTP/S header and message. As this is data-driven, an intelligent distribution of the incoming requests is possible. Even the tracking of responses can be done as they provide data regarding each server load when they travel back from the server.The most significant application layer algorithm is:
Least pending requests (LPR)
The pending requests are monitored and efficiently distributed across the most available servers. It can adapt instantly to an abrupt inflow of new connections, equally monitoring the workload of all the connected servers.
Benefits include Request specific distribution and Accurate load distribution.
The technique to be chosen mainly confides on:
i) Type of application/service being requested.
ii) Network and server performance at the time the request is made.
Simple balancing methods work with is less load, while complex techniques are required at busier times for an efficient request distribution.




