
Basics of Web Browser, Web Server, Big Data and Hadoop
- June 12, 2017
- 0
There are countless topics if we start talking about the Internet. We, like most people, simply search for specific terms or websites and do not bother much on how our tasks are performed. How our requests are carried out internally? In other words, how the server ‘serves’ us if we, through our ‘client’ browser, type something to fetch? Before diving into the depth of everything, I insist on the basics, first and foremost.
How do web browsers and web servers actually communicate?
The term web server refers to a software program that ‘responds’ to the HTTP requests asked by the user(s). The users do this with the help of their web browsers (a.k.a. clients) like Google Chrome, Mozilla Firefox, Safari, Opera, etc. ALL websites need web server programs, Apache for instance, in order to deal with everything.
You may imagine a restaurant (server) which is useless, if kept empty, and without its staff members (Apache software) it simply cannot enable the customers’ (users’) interaction, while they arrive.
The job of HTTP (HyperText Transfer Protocol) is to carry the requests made by user to the web server and bring back the resultant web page in response to the same. Today the HTTP is widely accepted because of its better efficiency than FTP. If a website still uses FTP, then instead of showing http: in the beginning, it will show ftp:. The File Transfer Protocol (FTP) is not in much use at present but was quite popular when the internet was initially introduced back then. It would help in uploading and downloading the files of any type of limited length.
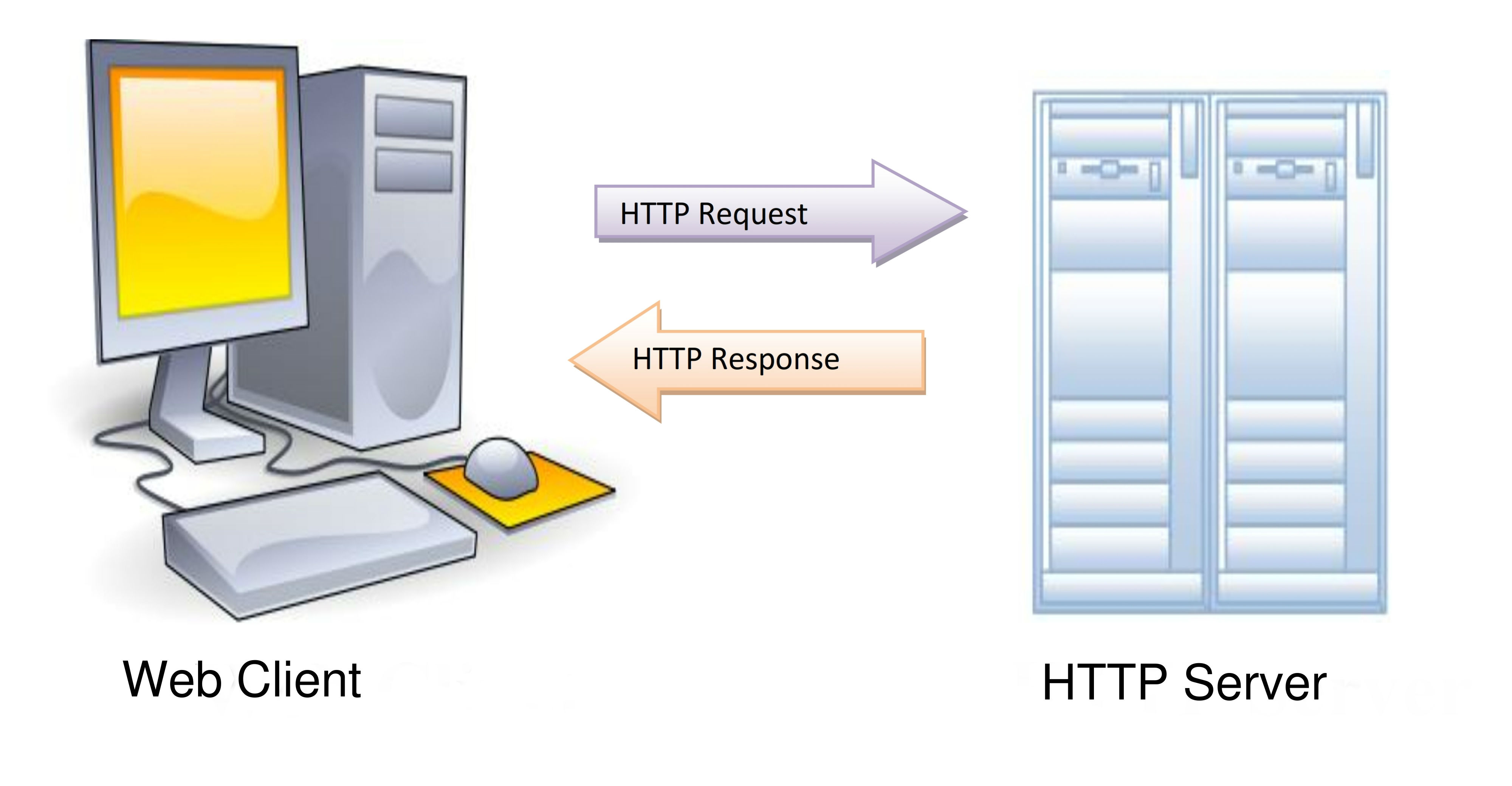 The whole piece of information is divided into small ‘packets’ that may approach same or different routes while getting transmitted. The source and destination is on the right track, all because of TCP/IP. TCP/IP basically stands for Transmission Control Protocol/Internet Protocol. IP is the unique address that each computer holds in this world. It is the IP address through which a client’s geographical location could be identified. Every client and server consist of this IP address so that the information could be easily exchanged. It is the job of TCP/IP to decode a particular URL address to the precise IP address so as to fetch the intended information, if it is present. Else it returns an error message (Remember 404?). Once the ‘packets’ arrive at the intended IP address, these together join into a whole piece of information, that an end user seeks.
The whole piece of information is divided into small ‘packets’ that may approach same or different routes while getting transmitted. The source and destination is on the right track, all because of TCP/IP. TCP/IP basically stands for Transmission Control Protocol/Internet Protocol. IP is the unique address that each computer holds in this world. It is the IP address through which a client’s geographical location could be identified. Every client and server consist of this IP address so that the information could be easily exchanged. It is the job of TCP/IP to decode a particular URL address to the precise IP address so as to fetch the intended information, if it is present. Else it returns an error message (Remember 404?). Once the ‘packets’ arrive at the intended IP address, these together join into a whole piece of information, that an end user seeks.
The web server is the subset of WWW, an abbreviation of World Wide Web. The World Wide Web is the collection of web pages that are found in the network of connected computers, aka the Internet.
What is Big Data?
Ever imagined how sites owned by Google, Facebook, YouTube, etc. manage their ever growing data? You must have noticed that Facebook has been dealing with countless types of data, like audio, video, user profiles with all the information like real-time Shares, Likes, Uploads, Comments, Messages, etc. How does it do that?
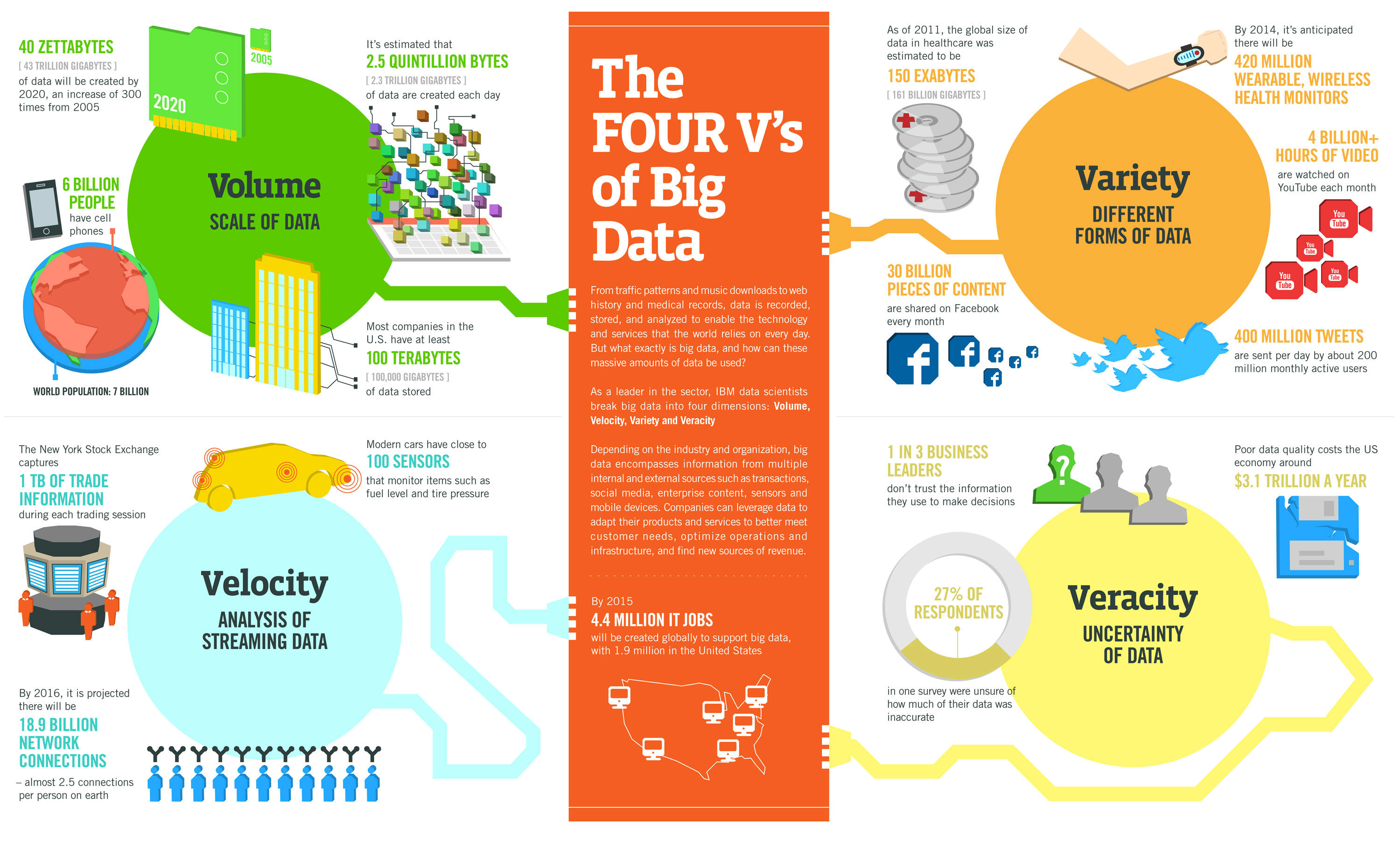
To handle such a large pool of data, there is a concept called Big Data. When the traditional data storage system is inadequate to deal with challenges like storing, capturing, sharing, transferring, visualizing, searching, updating, querying, etc., Big Data comes into the picture. It is very well handled by Hadoop, in order to maintain its functionalities.
What is Hadoop?
Hadoop is a specific kind of computational cluster that is designed to store and analyze unstructured large data sets (or Big Data) in a distributed computing environments. The clusters of Hadoop follow master-slave relationship with each other. There would be two main clusters designed as NameNode and JobTracker respectively. The rest clusters, that serve as slaves, would be both DataNode and TaskTracker.
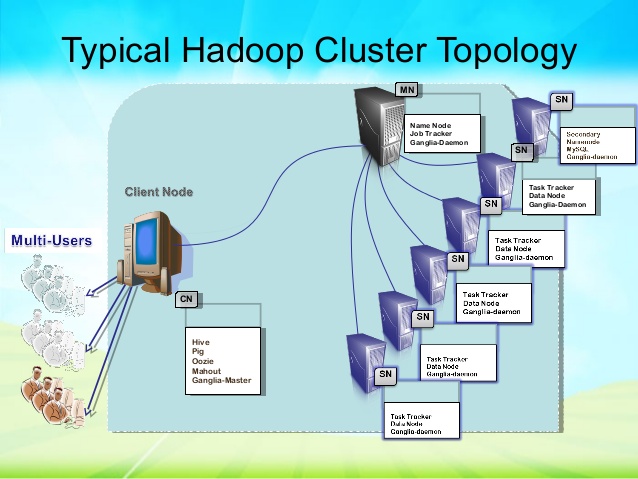
Hadoop clusters are widely used in order to boost the speed and the overall functioning of the existing servers. Since the data is continually growing, the clusters’ processing power does get overwhelmed at times. The problem could be solved by adding more cluster nodes. The data being stored inside the clusters are never permanently lost because each node has a separate copy of data. If one or more cluster nodes get dysfunctional by chance, the tasks are still continually run, without letting the end user actually know.
Apache Web Server
Apache is the most widely accepted web server open source software by Apache Software Foundation. Being the best of its kind, it therefore, takes over around 67% of the total web servers across the world. It is easily customizable to suit the wide range of environments and is hence mostly recommended by WordPress web hosting providers. It is possible that WordPress gets run on other web server software (other than Apache, such as Lighttpd and Nginx) as well.
What if the server performance goes down every now and then? How will you cope up with the slow server functioning if you somehow manage to divert most of the network traffic? Apachebooster plugin is an answer to your every query. It is a sophisticated cPanel based plugin that boosts the performance of a server to many folds and enhances its overall working capability. It is easy to install and requires relatively no maintenance. It is of high quality that comes within reasonable price range.
Author: Ankita Purohit




