
Apache Web Server and its overall working in detail
- June 16, 2017
- 0
Apache Web Server is an open source software that creates, deploys and manages the overall functioning of the web server. It was developed by a group of software programmers but now owned by the Apache Software Foundation. It currently holds over 50% of the global market share.
As discussed in the previous blog, the job of web server is to accept the clients’ requests and serve with relevant responses in the form of web pages, if available, else return an error message (404!). In case of static requests, the web server gets a URL, takes out the requested filename from the local disk, and sends it over the internet wherever it is intended. In case of dynamic requests, the URL gets translated into a program name, which then gets executed so that the output is sent over the internet back to the intended location. Apache can serve both dynamic as well as static contents. The term ‘web server’ could be referred to the machine itself that receives requests and responds with the results based on the circumstances.
“A web server is nothing but a computer device with a special software and functioning, and an internet connection so that other devices could get connected. This is how a valuable information transmission is possible.”
Apache Web Server is free to download and install easily, an open source software which suits all the requirements. The typical requirement could be two to three pages in a website, or a detail oriented site with thousands of pages. A website also might need to handle millions of (regular) visitors in a month, once it is launched. It must not crash, or even if it does initially, it must get fixed soon enough.
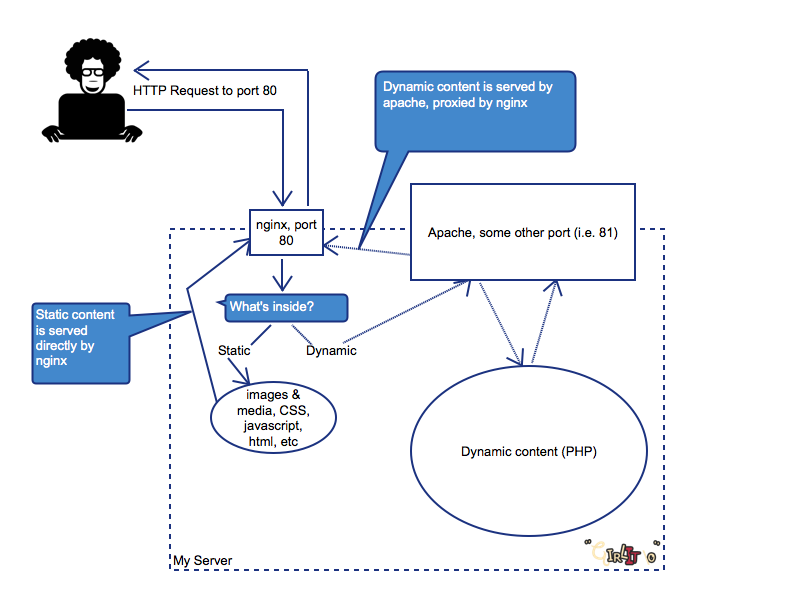
How does Apache web server work?
In an idle state, Apache server listens to various IP addresses that are being determined in its Config file. Whenever the requests are received, it quickly analyzes the headers and applies the protocols as specified in this file. This further helps take appropriate action, therefore making it a swift affair.
One web server can handle countless websites depending on its memory capacity and other crucial factors. To the outside world, it appears as if all the websites are independent, despite of the fact that all are going to eventually mapped to the same machine. The concept of virtual hosts comes into the picture where the sites are termed as virtually different.
“The method of hosting a wide range of domain names under the name of a single server or a pool of servers is what we call Virtual Hosting.”
The most famous examples of web hosting companies are – GoDaddy, HostGator, DreamHost, InMotion, Bluehost, 1&1, and A2 Web Hosting. Any firm, whether it is a start-up or an already established company, has a website and the domain is purchased online at one of the mentioned web hosting companies. The web hosting company has several packages at different prices. The buyers decide the best suitable ones, based on their current status of the business.
What is Apache HTTP server?
It is a list of codes (or a software program, to be specific), under relevant operating system, that runs in the background. It supports multi-tasking and serves other applications connected to it. Initially, it was designed for Linux and Unix operating system only but later its design was adapted to work under Macintosh and Windows as well.
Installing Apache on Linux operating system requires good programming skills but on Windows it is easy and straight forward because of the presence of GUI (Graphical User Interface). The source code of the Apache web server is very much basic, and therefore needs to have added functionality through many modules, being written by software programmers. This is how a server has extended functionalities. Appropriate modules are written based on the requirement.
In order to add a new module, just install that particular module and restart the Apache web server. If you don’t want a particular functionality, simply remove it so that the server becomes light and faster. It consumes lesser system resources and hence safeguards the server from security holes. Apache server also gets easily integrated with other third party open source applications, like MySQL and PHP. This makes it even more powerful.
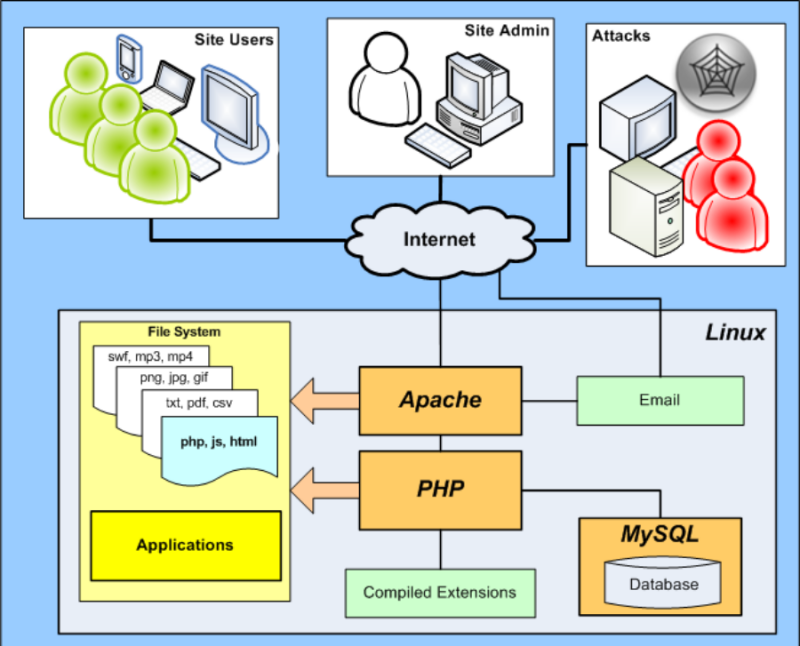
What goes on in the background while client and server communicate?
Most of us who deal with the internet surfing, websites and the world wide web are familiar with the Internet Protocol, aka the IP address. Every computer, laptop, mobile phone, and tablet has a unique IP address so that a successful information flow could be maintained. The information cannot be sent to any device in absence of an IP address, just like a letter cannot be sent to a house without an official postal address. It is responsible for determining the geographical location of any computer device residing in this world.
It is practically impossible to remember each technical IP address of every device. The solution given to the issue is – giving a separate domain name to each site. It is the job of DNS server to translate the user-friendly domain names to their original IP addresses (or vice versa) and serve it to the clients.
For example, you typed www.google.com and you obviously do not know its original IP address. The DNS server helps with the translation part so that the server ‘understands’ what the client is actually asking for. It will take out with the relevant site that has an IP address, say 216.58.216.164, which will display the Google’s page in front of you. Please note that Google has several IP addresses, depending on which server is currently serving you. Your purpose is served without worrying about any hassle of background working!
If the client types www.google.com at the browser’s address field, following request appears to the server:
GET / HTTP/1.1
Host: www.google.com
The GET method specifies which page (or program) needs to be retrieved. The forward slash ‘/’ denotes the root directory, and HTTP 1.1 denotes the HTTP version. HTTP is a stateless protocol that governs the communication between the client (requests) and the server (responses). If the request is successful, i.e. when the page is retrieved and is ready for display, following code would be executed in the background:
HTTP/1.1 200 OK
Date: Sun, 10 Jun 2017 19:19:19 GMT
Server: Apache
Expires: Wed, 15 Jan 1987 15:00:00 GMT
Cache-Control: no-cache, must-revalidate, max-age=0
Pragma: no-cache
Last-Modified: Sun, 10 Jun 2017 19:19:19 GMT
Vary: Accept-Encoding,User-Agent
Content-Type: text/html; charset=UTF-8
Content-Length: 7560
The status 200 determines that the requested page is successfully found and is ready for display. The header Content-Type lets the client browser know about the type of data so that it knows in advance the ways to handle it. Content-Length lets the client browser know the length of the response page body. Following code is executed in case the page is unable to get displayed:
HTTP/1.1 404 Not Found
The exact message is displayed depending on what string characters the programmer has written, and in what exact page-design. There are statuses other than just 200 and 404, and so depending on the situation certain status show up as per relevance. The information written here is just a tip of an iceberg. The programmers who actually do the coding part for servers are familiar with every crucial detail. To learn more about this, one must show enthusiasm towards websites’ programming.
Author : Ankita Purohit




