5 Different Types of Server Caching Strategies and How to Choose the Right One
- August 6, 2018
- 0
If someone owns a website, speed matters A LOT! This means if it gets loaded slowly it would repel away the potential consumers, and reduce the conversion rates. It is indeed a big deal for a business since it cannot grow if the situation is continued even for a while. Large amount of traffic can bring the server down and that could cost thousands (or millions) of bucks if the business is already established. Server caching helps to handle it all if done in a proper way. It greatly systematize the whole thing.
It is important to know the different types of server caching strategies in order to know how to choose the right one. This is because every site is different and so it should be prepared to serve everyone who requests to load. But, what if the number of requests are too large to tackle? How about sudden traffic spikes? Should it block further client requests after a certain time limit? Is that even feasible? Or should it learn to somehow serve everyone at any given point of time? The latter sounds competitive, doesn’t it? One must be familiar with different types of server caching strategies so as to choose the right one. Below are the most common ones:
5 Different Types of Server Caching Strategies
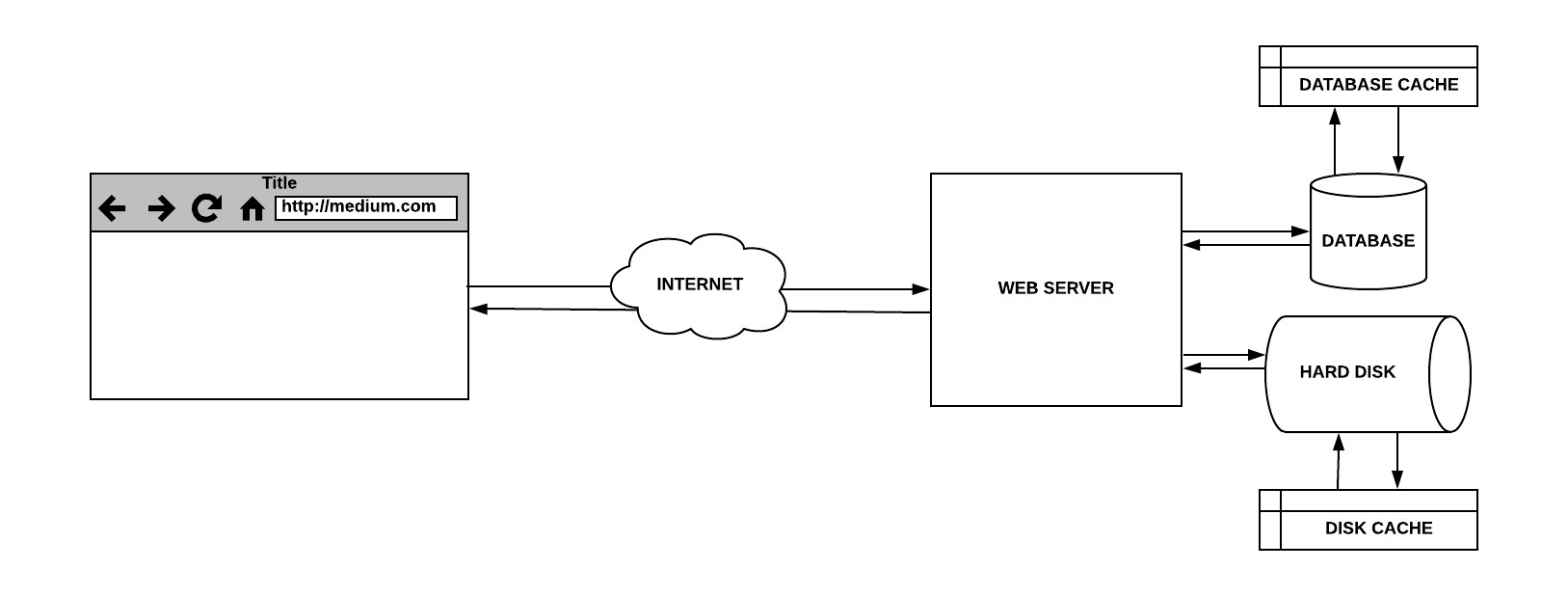
1. Cache-Aside
In this caching strategy, the cache is logically placed at the side and the application directly communicates with the cache and the database to know if the requested information is present or not. The cache is first checked by the application. If the information is found, it is marked as cache hit, and so, it is read and returned to the client. If the information is not present, it is marked as cache miss. The application queries the database for reading the data, returns the read data to the client, and then stores it in cache for future cache hits.
It works best for read-heavy workloads. If the cache server is down, the system still works by directly communicating with the database; though that is never a long-term solution in case of peak load that suddenly hits at times. The cache server requires to be fixed soon. The data model can be different in cache and that of the database.
The most common writing strategy is to write directly to the database. This brings data inconsistency, and to deal with this, the developers generally use TTL (time to live) and continue serving until it expires. It could also be collaborated with other server caching strategies as described in the next paragraphs.
2. Write-Through Cache
In this method, the information is first written to the cache before the main memory/database. The cache is logically in between the Application, through which the client interacts, and the database. Therefore, if a client requests for anything the application does not have to check in the cache for its availability since it is already there. It directly retrieves from the cache memory and serves the client.
On the downside, it increases the write latency; but if paired with read-through cache (another strategy written just next) we get the guarantee of data consistency.
3. Read-Through Cache
In this method, the cache sits inline with the database. Whenever there is a cache miss (meaning, the requested data isn’t in the cache), the missing data is populated from the database and gets returned to the application, so that the client is served.
It works best for read-heavy workloads when the same set of information is requested several times. For instance, a news story that needs to be loaded over and over again by many people on different devices.
Its main disadvantage is, if the data is requested for the first time, it is always a cache miss, thereby loading it way too slowly than normal. The developers deal with it by issuing queries manually or by write-through cache.
4. Write-Back
In this server caching strategy, the application writes the information to the cache that immediately acknowledges the changes, and after some delay, it writes back the data to the database. We can also call it write-behind.
It is a good strategy for write-heavy workloads that improves the write performance. It can tolerate moderate database downtime and failures that take place at times. It works good with read-through cache. If batching is supported, it can reduce the overall writes to the database, thereby decreasing the load and costs.
In most relational database storage engines, such as InnoDB, the write-back cache is enabled by default in which the queries are written to memory at first and then flushed to the main disk later. The major disadvantage is, if there is a cache failure, the data may get permanently lost.
5. Write-Around
In this case, the data is directly written in the database and only that data is stored into the cache which is read.
It can be combined with read-through cache. It is a good choice in situations in which the data is written once and is read negligibly or never. For instance, when there is a need of real-time logs or chatroom messages. It can also be mixed with cache-aside.
It is not necessary that either of the above mentioned types of server caching strategies ought to be in practical use, but one could also go with the combination of two or more for best results. If somebody is new to handle this, they need to do trial-and-error in order to come up with the best solution. It is possible that the strategies that were used before may get outdated later. This is why one cannot say that a particular method would always work for everyone.




