What is Kubernetes – Basic Concepts in simple words
- November 22, 2018
- 0
What is Kubernetes?
Kubernetes is a robust open source orchestration tool developed by Google for operating microservices or containerized applications beyond a distributed cluster of nodes. Kubernetes produces very flexible infrastructure with zero downtime deployment capacities, automated rollback, scaling, and self-healing of containers.
The principal purpose of Kubernetes is to mask the complexity of maintaining a fleet of containers by implementing REST APIs for the functionalities needed. It is compact in nature which indicates that it can work on several public or private cloud platforms such as AWS, Azure, OpenStack, or Apache Mesos. It can also operate on simple machines.
Kubernetes Components and Architecture
Kubernetes observes a client-server architecture. It’s likely to have a multi-master setting for great accessibility, but by default, there is an individual master server which functions as a supervising node and point of connection. The master server consists of several components including a Kube-API server, an ETCD storage, a Kube-controller-manager, a cloud-controller-manager, a Kube-scheduler, and a DNS server for Kubernetes services. Node components incorporate Kubelet and Kube-proxy on top of Docker. Following are the major components observed on the master node:
- ETCD cluster: A pure, distributed key-value storage which is utilised to save the Kubernetes cluster data, API objects and service identification details. It is only available from the API server for safety analyses. ETCD allows information to the cluster about configuration modifications with the assistance of watchers. Notifications/information are API requests on each ETCD cluster node to activate the update of data in the node’s storage.
- Kube-API server: Kubernetes API server is the principal administration object that accepts every REST requests for changes (to pods, services, replication collections/controllers and many more), working as a frontend to the cluster. Besides, this is the single component that interacts with the ETCD cluster, making sure data is collected in ETCD and is in accordance with the service specifications of the deployed pods.
- Kube-controller-manager: Operates many distinguished controller processes in the environment (for example, replication controller manages a number of replicas in a pod, endpoints controller occupies endpoint objects like services and pods, etc.) to control the shared state of the cluster and make regular responsibilities. When a difference in a service configuration happens, the controller detects the change and begins running towards the new aspired state.
- Cloud-controller-manager: This component is capable for operating controller methods with dependencies on the underlying cloud provider. For instance, when a controller requires to verify if a node was stopped or set up paths, load balancers or volumes in the cloud infrastructure, all that is managed by the cloud-controller-manager.
- Kube-scheduler: It helps to schedule the pods on several nodes based on resource usage. It scans the service’s operational specifications and lists it on the choicest fit node. For instance, if the applying needs 1 GB of memory and 2 CPU cores, then the pods for that application will be scheduled on a node with a minimum of those resources. The scheduler works each time there is a requirement to schedule pods. The scheduler needs to understand the entire resources ready as well as resources designated to current workloads on every node.
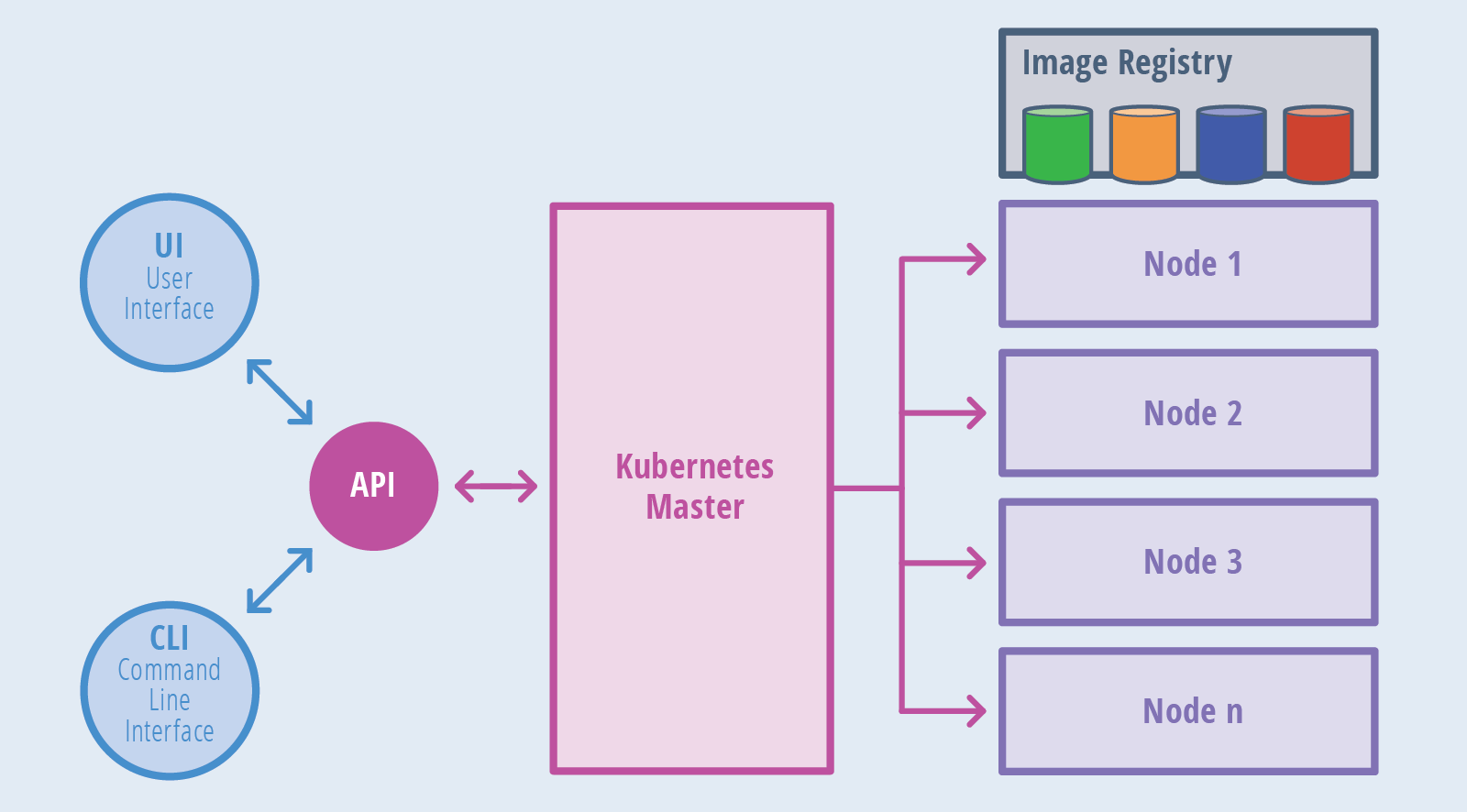
Node (worker) components
Hereinafter are the chief components observed on a (worker) node:
Kubelet: The chief service on a node that constantly takes in new or changed pod specifications and assuring that pods and their containers are in good condition and working in the expected state. This component also communicates to the master on the fitness of the host where it is working.
Kube-proxy: A proxy service that works on all worker node to deal with individual host subnetting and present services to the outer world. It does request forwarding to the exact pods/containers over the multiple isolated networks in a cluster.
Kubernetes Basic Concepts
To utilise the Kubernetes, it is important to know various concepts it works, for instance, services, pods, volumes. namespaces and deployments.
Pod: Pod usually indicates single or multiple containers that should be managed as a separate application. A pod confines application containers, storage resources, a unique network ID and other configuration on how the containers work.
Service: Pods are unstable, that is Kubernetes does not ensure an assigned physical pod to be active. Rather, a service depicts a logical set of pods and performs as a gateway, enabling (client) pods to send requests to the service without requiring an observation on which physical pods really make up the service.
Volume: Kubernetes volume is comparable to a container volume in Docker, but here volume indicates to an entire pod and is installed on each container in the pod. Kubernetes ensures data is conserved over container restarts. The volume will be eliminated only when the pod gets damaged. Also, a pod can have many associated volumes of different types.
Namespace: A virtual cluster (a single physical cluster can manage multiple virtual ones) is designated for settings with numerous users scattered across many teams or projects, for separation of businesses. Resources in a namespace must be uncommon and cannot locate resources in another namespace. Additionally, a namespace can be allotted a resource quota to avoid spending more than its share of the physical cluster’s overall resources.
Deployment: Specifies the desired state of a pod or a duplicate set, in a YAML file. The deployment controller then successively updates the context (for example, creating or deleting replicas) till the current state equals the desired state specified in the deployment file. For example, if the YAML file represents 2 replicas for a pod but only one is currently working, an additional one will get produced. Be aware that replicas maintained via a deployment should not be managed directly, It should be performed only through new deployments.
What are the Kubernetes Design Principles?
Kubernetes was sketched to help the features needed by profoundly accessible distributed systems, for example, (auto-)scaling, high availability, safety and portability.
Scalability – Kubernetes presents horizontal scaling of pods on the grounds of CPU utilization. The threshold for CPU usage is configurable and Kubernetes will automatically begin new pods if the threshold is reached. For instance, if the inception is 70% for CPU but the application is really turning up to 220%, then ultimately 3 more pods will be deployed so that the average CPU utilization is back under 70%. When there are many pods for separate applications, Kubernetes implements the load balancing capacity over them. It also helps horizontal scaling of stateful pods, comprising NoSQL and RDBMS databases through Stateful sets. A Stateful set is a related concept to a Deployment but assures storage is determined and constant, even when a pod is eliminated.
High Availability – High-availability Kubernetes marks large availability both at application and infrastructure level. Replica sets ensure that the desired number of replicas of a stateless pod for a distributed application are operating. Stateful sets make the same role for stateful pods. At the infrastructure level, Kubernetes assists unevenly distributed storage backends like AWS EBS, Azure Disk, Google Persistent Disk, NFS, and more. Adding a secure, available storage layer to Kubernetes ensures high availability of stateful workloads. Also, all of the master components can be configured for multi-node replication to ensure greater availability.
Security – Kubernetes addresses protection at various levels like cluster, application and network. The API endpoints are guarded through transport layer safety (TLS). Only verified users having service accounts or normal users can perform actions on the cluster through API requests. At the application level, Kubernetes secrets can collect sensitive information per cluster. Note that secrets are available from any pod in the same cluster. Network policies for access to pods can be settled in a deployment. A network policy defines how pods are provided to interact with each other and with other network endpoints.
Portability – Kubernetes portability discloses in terms of producing system options, processor architectures, cloud providers, and new container runtimes, besides Docker, can also be combined. Within the concept of federation, it can also hold workloads across hybrid (private and public cloud) or multi-cloud circumstances. This also maintains availability zone fault tolerance within a single cloud provider.
Kubernetes is quickly growing in the operating system for the Cloud and produces a universality which has the potential for huge profits for technology corporations and developers. Kubernetes has seen an exciting improvement in clarity and choice throughout 2017, with all important cloud providers now allowing their own native Kubernetes service, and various container orchestration platforms reconstructing with Kubernetes as a foundation. That’s all about Kubernetes’ basic concepts in simple words!




