Understanding Apache Kafka for Beginners
- June 5, 2018
- 0
Initially developed in January 2011 by LinkedIn, Apache Kafka is now officially owned by the Apache Software Foundation, whose latest release occurred quite recently in 28th March 2018. It is an open source stream-processing software platform which is written in Java and Scala. Its main aim is to provide a high-throughput, unified, and low-latency software platform so as to tackle the real-time data feeds. It has gained huge popularity lately that not only LinkedIn but also lots of other companies have gained trust over it and use this technology with confidence. This is because a list of benefits it offers.
Understanding Apache Kafka
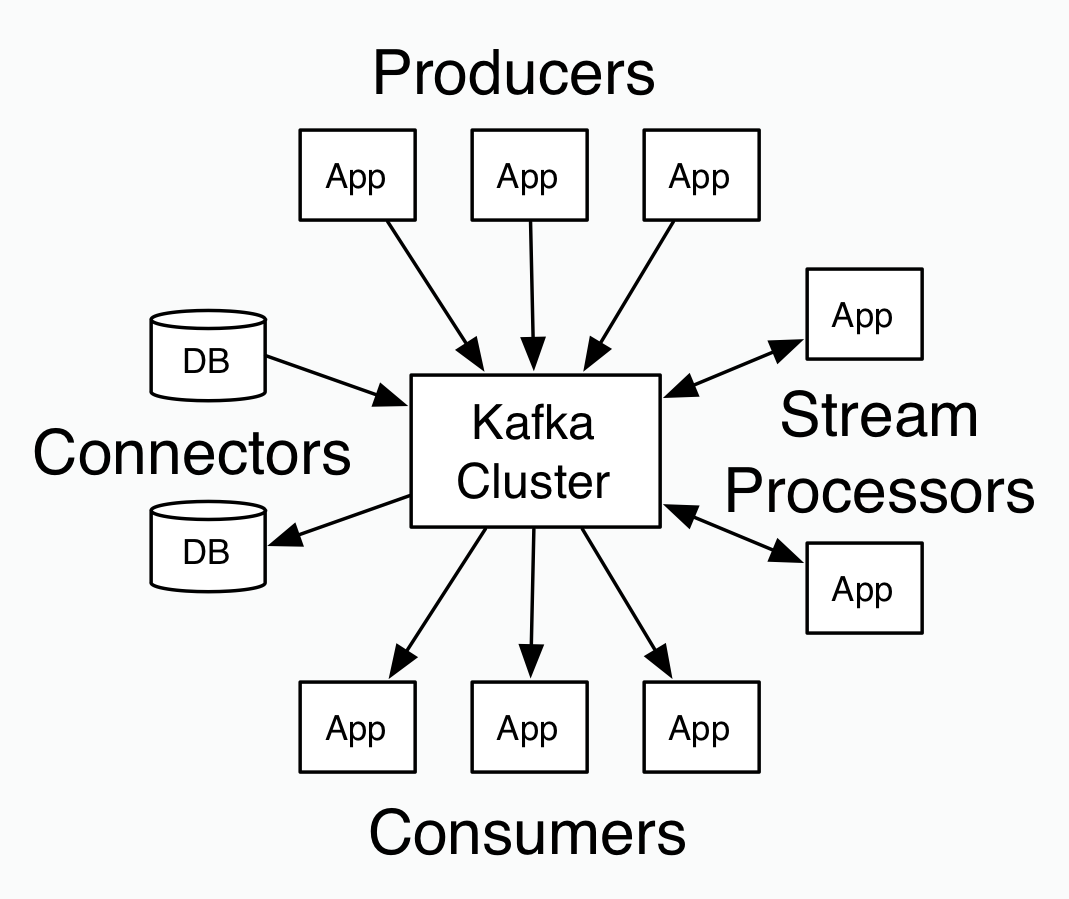
Kafka is a distributed messaging system which is based on publish-subscribe method and is fast, durable, and scalable. It maintains message-feeds in different streams called topics. The job of producers is to write new data to topics and the consumers are supposed to read those created data from topics. Since it is a distributed system, the topics are divided and replicated across multiple nodes. Whatever data has been written on topics may be read by one or more users depending on the type of subscription they have.
The developers use the messages that are nothing but byte arrays. In order to store an object in any format, be it JSON, String, and Avro. a key could be attached to each message ensuring that all the messages will arrive to the same partition if the keys find the exact match.
In a consumer group, each customer will read messages that belong to a unique subset of partitions to which they are subscribed. Apache Kafka treats each topic partition as a separate log. Each message contained in a partition is assigned a unique offset. Kafka keeps track of all the messages for a set amount of time irrespective of them being read or not. The customers are supposed to track their location through each log. Apache Kafka is capable to handle bulk of consumers and hold their large amount of data.
It can be well explained using a real-time example. So, let’s take an example of an online game of multiple users where virtually the players fight/compete with each other to get rewards. It is common for the players to exchange game items and money. Hence, the game developers have to write code in such a way that the users never get the chance to cheat.
Suppose the trade amount is substantially higher than average and the IP that is used to login is different than the IP being used in the last 20 games, it would then be flagged within no time. Other than just flagging in real-time, the data needs to be loaded to Apache Hadoop where the data scientists would be using it to train and test the new algorithms.
In real-time flagging, the decision and actions need to be real quick, and that could be effectively achieved if the data is being cached on the game server’s memory for most active players. The system keeps multi-servers for games and the data set has the last 20 logins plus last 20 trades for each user can be well fitted in the memory if the partition is done between these servers.
The game servers have two roles to perform – accept and propagate user actions in real-time, and flag the suspicious events. In the latter case, a complete history of trade events that occurred for each user needs to be resided in the memory of a single server. The server that tends to accept the current actions of users may not be having his trade history, and so, there comes a requirement of passing the messages between the servers. In that case, Kafka is being used.
Kafka has all the required features that one would require to handle bulk of consumers – data partitioning, scalability, low latency, and the capability to tackle diverse consumers. It was initially developed to make data ingest to Hadoop. If there are countless sources and destinations to involve, it becomes unmanageable to write a separate data pipeline for each source and destination pair. Apache Kafka helped LinkedIn a lot to standardize the data pipelines, thereby allowing to get information out of each system one time and into each system one time. This substantially reduces the pipeline complexity and cost.




