Apache Hadoop – Why is it important to handle Big Data?
- July 17, 2017
- 0
When the traditional computing techniques find hard time in handling several kinds of complex data, one needs to change his/her approach. Many of you might be familiar with Big Data which is, conceptually speaking, a large dataset of countless types of information being stored in such a way that storing, manipulating, updating, etc. become easy because of software applications like Apache Hadoop. Apache Hadoop is a software application framework which enables such a surplus amount of data to be streamlined using simple programming models.
The Big Data is handled using distributed processing system across computer clusters. The software framework is designed in such a way that any kind of error or failure could be detected and resolved without actually affecting the server and its audience. The corrections are done in a manner which won’t be noticeable to the end-users.
Following are the activities that are performed while dealing with Big Data:
1. Storing – It is not just a general account information that you might expect in a database, for instance, data like username and password. It is much more like audio or video files of varying space, postal address of any length, live streaming of data of any kind, never ending blog updates on websites, and so on.
2. Processing – This involves running countless algorithms, calculating, cleansing, updating, and transforming the existing as well as new data. This requires special types of software because traditional data management would delay everything and that would be easily noticeable.
3. Accessing – ANY kind of data, whether complex or not, ought to be accessed easily. If it is not done in the right and hassle-free manner, there is no point of even storing it! Why? Because you won’t be able to retrieve it as per your own terms and it might seem being lost. Apache Hadoop makes this task easy.
Hadoop’s Community Package consists of the following:
-
JAR (Java ARchive) files
-
MapReduce or YARN engine
-
HDFS (Hadoop Distributed File System)
-
Scripts to enable Hadoop to get started
-
File system and OS level abstractions
-
Source code, documentation and contribution sections
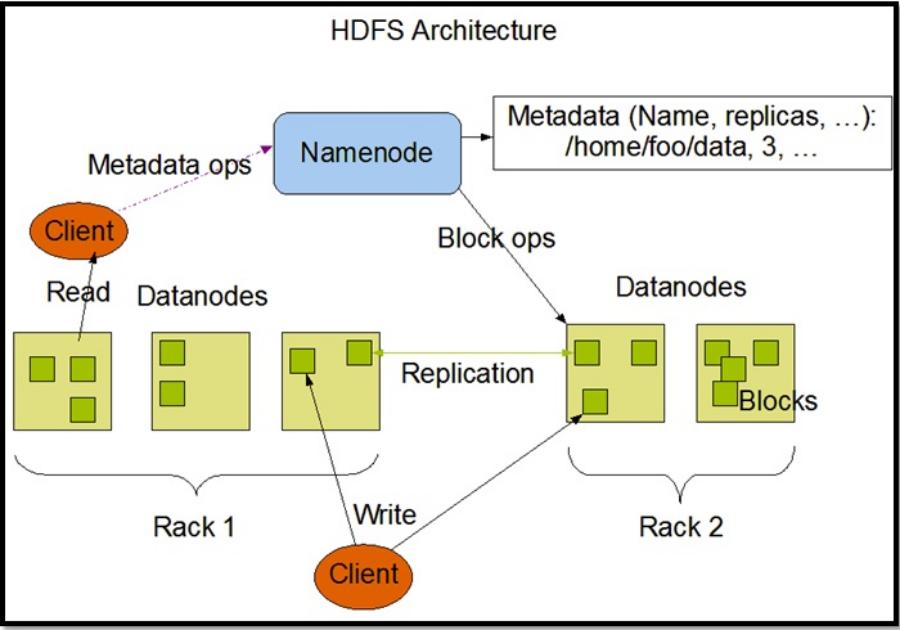
Hadoop Distributed File System (HDFS)
HDFS, being one of the Hadoop’s two main parts (other than being Data Processing Framework), is there for the rescue of managing extremely large files, typically ranging between gigabytes to terabytes, across a wide range of machines. The job of job tracker is to schedule map or reduce jobs to task tracker, both of which simplify the overall data management. HDFS was designed in order to:
-
Tackle hardware failure
-
Design very large data sets
-
Handle portability issues
-
Stream data access
-
Enable coherency model
Apache Hadoop is there to address the capacity and difficulty of Big Data environment, that also involves structured, unstructured and semi-structured mix of data.
Data Processing Framework
MapReduce, a Java based system, is what used to process the Big Data’s Data Processing Framework tool.
JobTracker and TaskTracker
The JobTracker Master manages the entire process, from assigning tasks to workers, monitoring each task, and handling the failures, if any, shows up. The JobTracker also makes work available to TaskTracker nodes, aiming for keeping the work closest to data as possible in the cluster. The JobTracker is familiar with the overall architecture and so it also reduces the heavy network traffic by diverting the racks and their corresponding nodes.
Scattered Clusters
The Big Data is distributed across clusters, on different machines, and the data processing software resides on another server. The MapReduce system, data within HDFS, and Hardtop clusters reside on each machine in the cluster in order to speed-up the processing and information access/retrieval.
If a failure occurs, it does not take much time in accessing that information as well because each cluster has a copy of everything. Keeping all kinds of information in each cluster located in varying geographical location helps end users access what they expect, in lesser intervals.
Since the data is always growing on the Web, it is necessary to analyze it in order to better understand the overall patterns and correlations exist among them all. This analysis in general is useful while detecting the consumers’ buying tendencies, quite useful strategy in regards to hold marketing point of view in the eyes of merchant(s). It is divided into three categories:
1. Relational data (digital database)
2. XML data on WWW, intranets, etc.
3. Word, PDF, Text, Media data, etc.
Advantages of Big Data Analytics
1. Big Data analysis helps to visualize, analyze, find, extract, and acquire the data with tools like SAP.
2. It helps improving the decision making quality.
3. It also quite well addresses the scalability, security, mobility, stability, and flexibility.
4. It monitors the real-time live streaming of events that impacts the merchant’s business performance.
Hadoop has many advantages which is why it is being used by renowned firms like Facebook, Yahoo, Twitter, Google, and even while dealing with Fighter planes, Airplanes, Helicopters, Space shuttles, in aerospace domains. The system captures the crew members’ voices while they communicate with each other live. It also keeps records of their earphones and microphones, for future use, if required. These kinds of data can now be stored, which was not possible decades back.




